
One of the challenges with building AI architecture is choosing the right model. The general assumption before you get to the point of having to make a choice is that most generative models are similar. This assumption is far from reality, especially when dealing with open-weight models.
As we continue to transition to an AI-native paradigm that places LLMs at the core of digital interactions, understanding the decision criteria will become the centrepiece of strategic design. This is akin to selecting the best chassis before building a car. But unlike a physical vehicle, which is constrained by physical limitations, we can use specialized techniques to work around them in the digital world.
1. Start with a clear understanding of the project's objectives: For example, my project involves 8K document ingestions for summarization.
2. Understand your hard limits: This refers to hardware limitations, since LLM projects are constrained mainly by the GPU's memory capacity. For instance, I run my projects on an RTX 5090, which has 32GB of VRAM. This is the hard limit for my environment if I want to use the GPU via vLLM for optimal performance.
3. Define the scope of what you want the model to excel at: I needed the best Text-2-Text model that will hit my hardware limits.
Knowing the boundaries of my projects, I settled on Qwen2.5 to replace GPT-OSS-20B.
Below is an example of comparisons of Qwen2.5-32B-instruct and GPT-OSS-20B
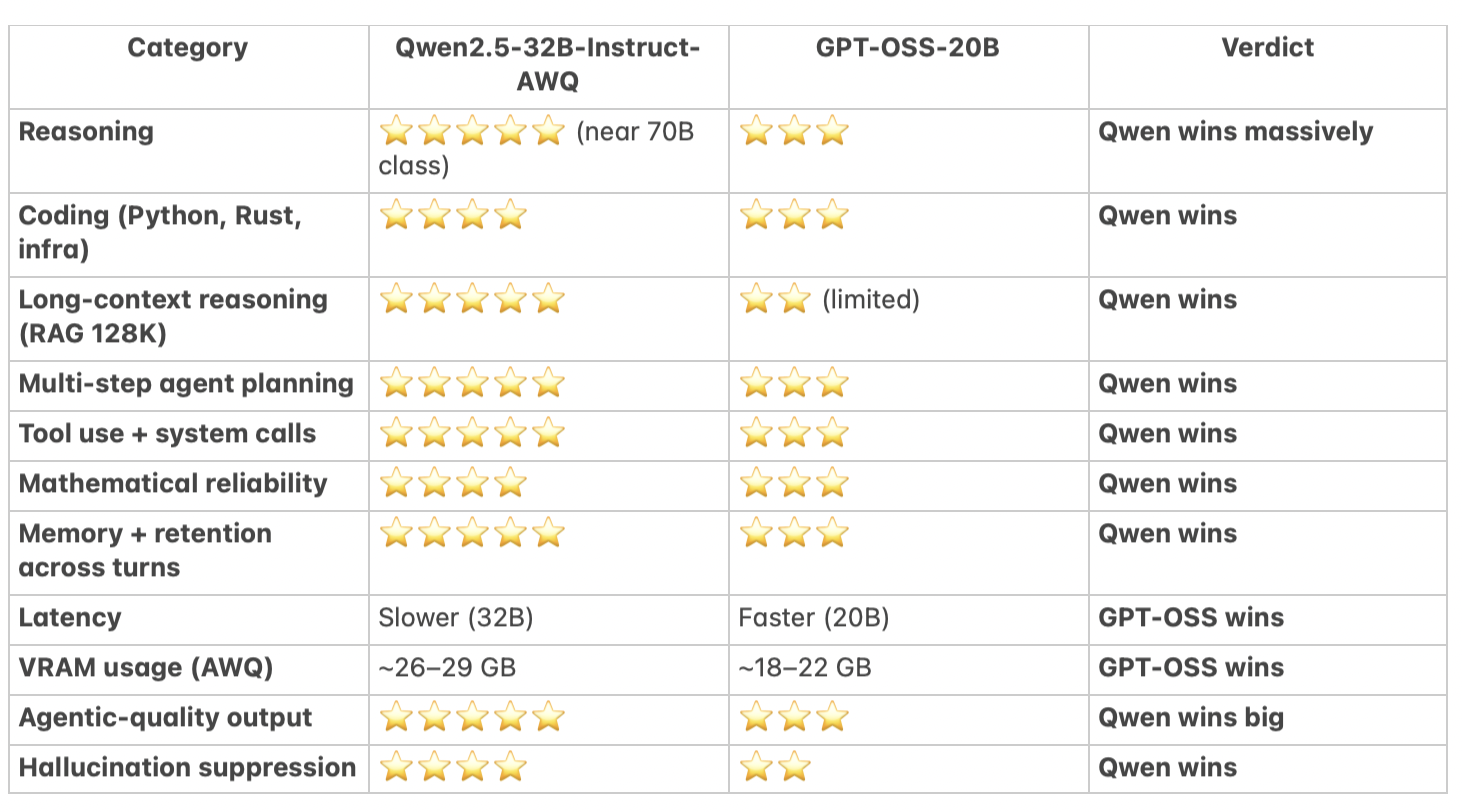
For functional overview, I compiled a list of my use-cases and used ChatGPT 5.1 to analyze which model will serve the project pipeline the best:
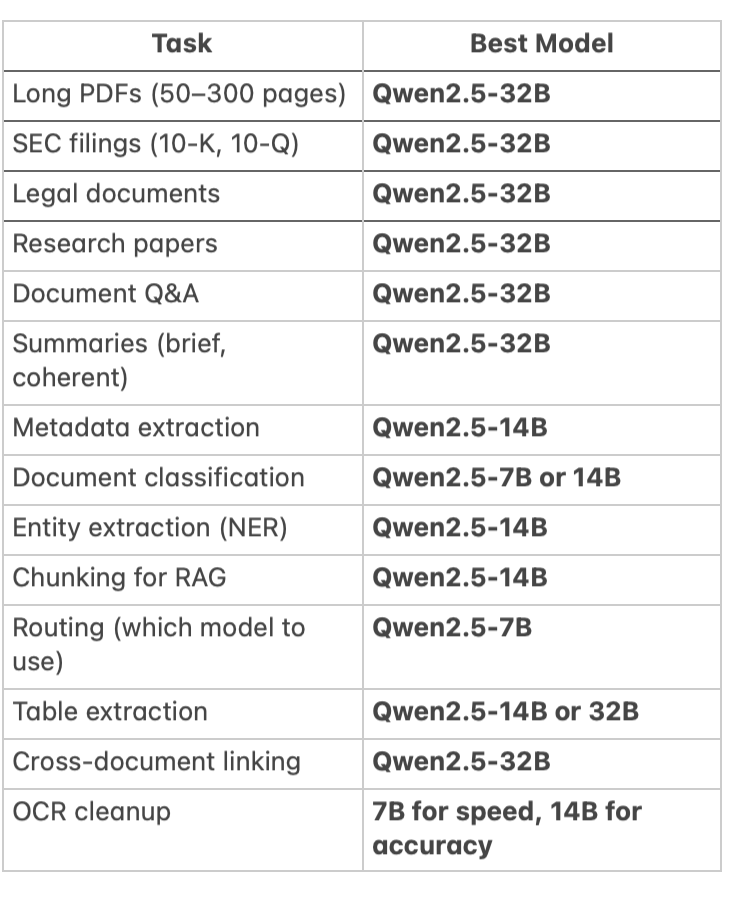
Conclusion
In the scope of an ever changing LLM landscape, it is important to maintain functional level awareness of design choises and their implications before starting an LLM project. Or even beter, ensure the design considers a modular approach that will enable future enhancement without a complete rework. This a plug-and-play approach that can allow the project to benefit from new model discovery and seamless integration into an existing LLM stack.