
A common mistake when building a document question-answering system is assuming that every failure is due to the model itself. If the model cannot satisfactorily answer a question that you know is in the document ingested, the instinct is often to replace it with a bigger, newer, or longer-context model.
This article explains why designing LLM architecture goes far beyond simply increasing the model’s parameter count or context window.
The Use Case:
The pipeline was designed to:
• Process arbitrary documents
• Classify them
• Chunk them into sections
• Embed them
• Store them
• Retrieve relevant sections
• Answer questions using an LLM
During recent testing of a retrieval pipeline using Qwen3-32B-AWQ running on a single RTX 5090 (32GB VRAM), an interesting issue occurred. The RTX 5090 can theoretically support mid-sized open-weight models comfortably - including GPT-OSS 20B, quantized Gemma 3 27B, Mistral 14B, and Qwen3.5 35B-A3B. But in production, you will start to run into challenges because of other variables such as caching required for KV that are not always accounted for.
For an exercise, we built an initial pipeline around Qwen3-32B-AWQ and later migrated to Qwen3.5-35B-A3B for improved reasoning and efficiency. And despite the hardware being sufficient, the model failed to answer questions about documents that clearly contained the answer.
At first glance, it seemed like a model intelligence problem, but it wasn’t. It was a pipeline design problem.
The Conventional RAG Pattern
Most systems follow this approach:
1. Extract text
2. Chunk text
3. Embed chunks
4. Store in vector DB
5. Retrieve top-k chunks
6. Send to LLM
7. Generate answer
This works in theory. But it is far too simplistic for real-world document reasoning. Illustratively, large chat models do not operate this way internally. Production systems require more structure and discipline. Files also come in so many different formats that make it challenging to have a simple RAG approach to creating a scalable knowledge system.
Improving the Ingestion Pipeline
Instead of increasing model size, we redesigned ingestion. We moved toward a “Two Brains in a Skull” architecture, separating lightweight precision cognition from deeper synthesis.
Enhanced Pipeline:
1. Ingestion
2. Normalize and deduplicate
3. Structure and section documents
4. Chunk with embedding constraints
5. Embed
6. Index
7. Enrich via classification
The key insight is that intelligence at query time depends on discipline at ingestion time. There is also the small matter of latency. Ideally, you want response to be within 5-7 seconds.
Blending the Cognitive Gradient: 3B + 14B
Cognitive gradient is the continuous transitions in structural architecture between the models and retrieval. To support this pipeline, we adopted a dual-model strategy - Small Language Model (3B parameters) and a Large Language Model (14B parameters).
Qwen2.5 3B - for basic reasoning. This is perfect for quick fact lookup, extraction for semantic classification, and retrieval of grounded responses that are structured and straight to the point. SLM is token-efficient and also reduces the risk of hallucination.
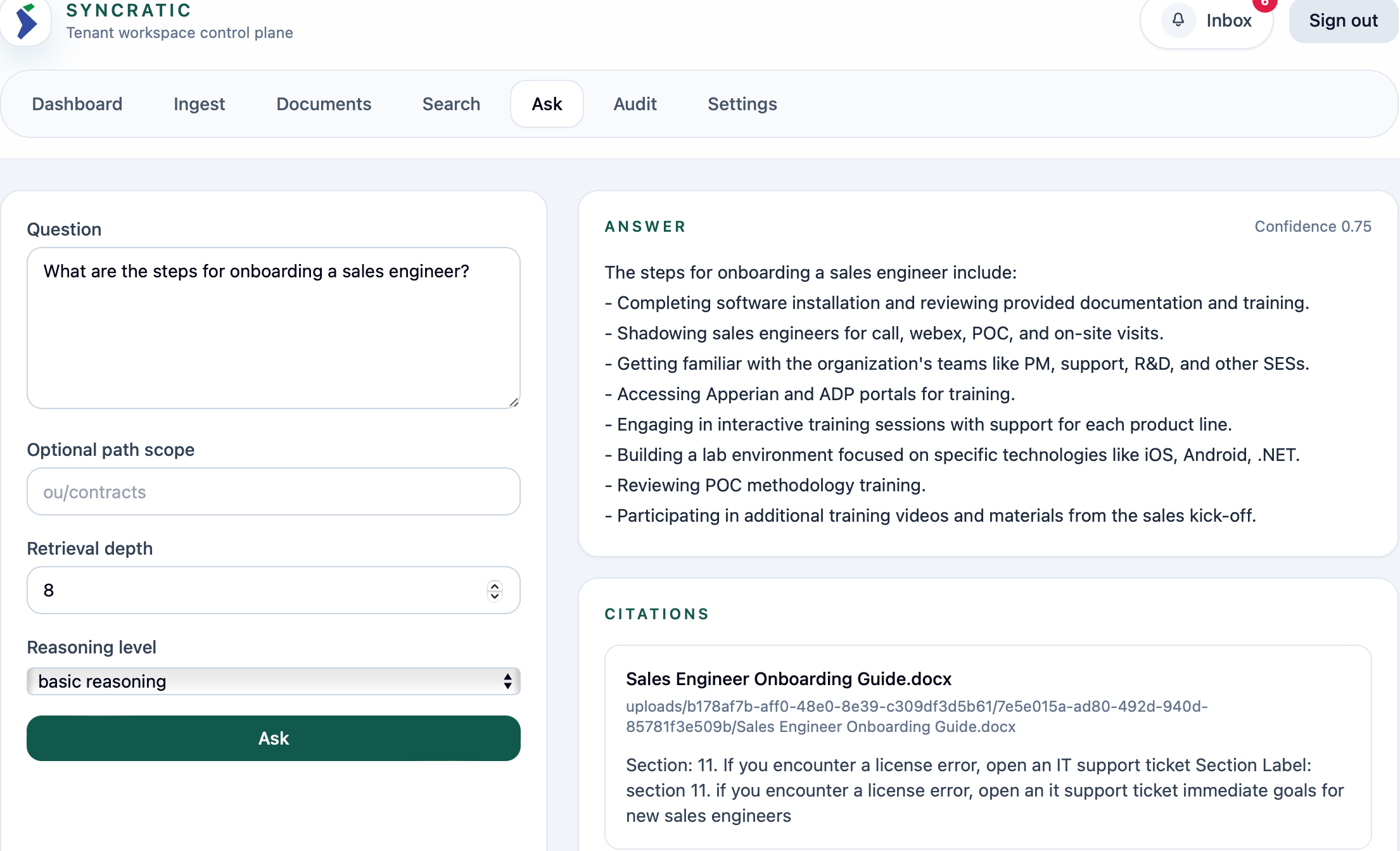
Qwen3 14B AWQ - for deeper reasoning: This is great for multi-document reasoning and broad synthesis to cross-reference context, making it intentionally expansive in production. This is where trade-offs emerge. The 14B model consumes more tokens and requires stricter budgeting.
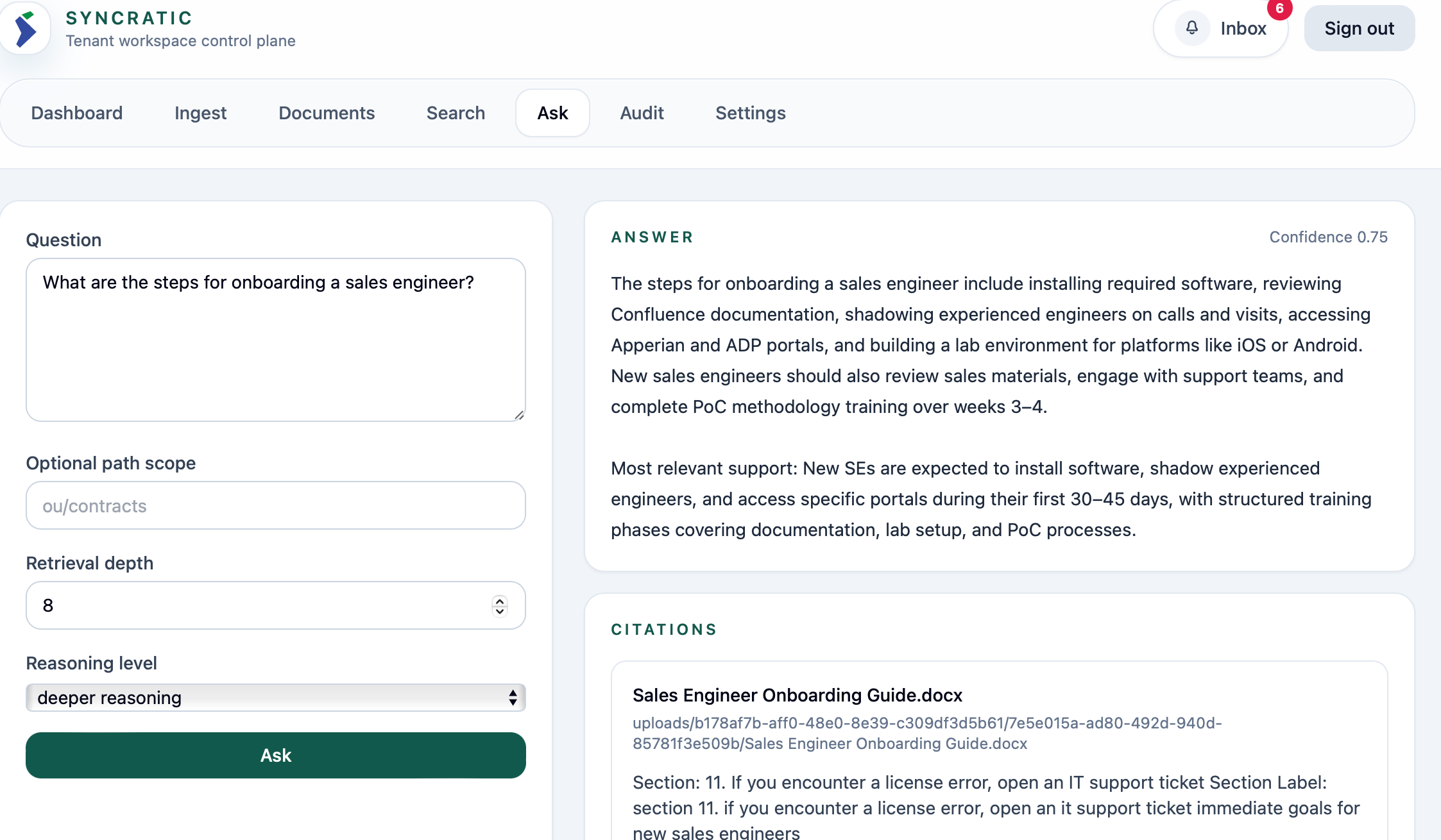
To improve performance, it is natural to assume that GPU utilization and VRAM will be the main bottlenecks. However, the actual limiting factors when designing production-grade infrastructure are:
• Token budgeting
• Routing discipline
• Chunking strategy
• Thinking mode
• Embedding boundaries
Scaling the Infrastructure
Building a scalable LLM infrastructure begins with understanding the problem that needs to be solved. For example, in a document knowledge system, it is important to know the size limits of the documents and how much inner reasoning the model must perform to process prompts before generating a response. You will need a different tokenss a 5,000-word legal document v budget to proceersus an 800-word guide.
Things to think about when designing the AI infrastructure:
Context Variables
• --max-model-len
Defines the upper bound of cognitive scope, directly trading reasoning breadth for memory pressure and latency.
• KV cache usage
Reflects how much real-time memory the model consumes per token, scaling linearly with context length and concurrency.
• Prefix cache efficiency
Measures how effectively repeated prompt scaffolding is reused, directly reducing latency and GPU load.
Generation Variables
• max_tokens
Caps the model’s expressive depth, determining whether reasoning completes or truncates under pressure.
• thinking / deep_mode
Amplifies internal deliberation, increasing token burn and latency in exchange for higher abstraction capacity.
• finish_reason behavior
Reveals whether generation ended naturally or was forcibly truncated, serving as a diagnostic for token budgeting accuracy.
Throughput Variables
• --max-num-seqs
Controls concurrency, balancing system throughput against deterministic latency and memory stability.
• --max-num-batched-tokens
Defines batching density, trading GPU efficiency for potential volatility in memory allocation.
• Batching behavior
Determines how requests are grouped for execution, directly impacting latency consistency and hardware utilization efficiency.
Precision Variables
• Embedding token cap
Sets the semantic granularity ceiling, forcing chunk boundaries to respect vector model limits.
• Chunk size discipline
Governs retrieval signal clarity, where oversized chunks dilute relevance and undersized chunks fragment meaning.
• Retrieval section selection
Filters contextual noise by constraining which document segments are eligible for synthesis.
Hardware Strategy Variables
• dtype (fp16 vs quantized)
Balances reasoning fidelity against VRAM footprint, trading marginal quality for hardware accessibility.
• kv-cache-dtype
Compresses memory used for attention state, impacting scalability more than reasoning capability.
• gpu-memory-utilization
Sets the ceiling for VRAM allocation, influencing stability, concurrency headroom, and fragmentation risk.
The Math of Concurrency
The great thing with building LLM infrasturature is that we can mathematically plan out what is needed to facilitate the expected consumption before the configuration. This removes the art of trying to figure it out in production. Therefore, to really address the issue of scalability of an architecture, it is imperitive to quantify the question of concurrency upfront. It is one thing getting the right model that work for the use case, but it quiet another thing ensuring that it will scale well in production.
Let's do the math on a small scale of RTX 5090 which has a VRAM of 32GB.
There are two key factors that consume VRAM:
1. Model weights (static)
2. KV Cache (dynamic)
The model weight is fixed when loaded, but KV cache grows with every token in the context window. That latter part is what turns the configuration into a 'science-art' exercise at the design phase.
First: Avaiable memory (VRAM)
Available_VRAM = (Total_VRAM × utilization_factor) − Model_VRAM
Second: Cost of each request - this is where the variables start to kick in
Each token in the context requires attention state storage:
KV_per_token ≈ 2 × hidden_size × bytes_per_element
The context length within the request consumes memory linearly:
KV_per_request = KV_per_token × context_length
When the context length doubles, VRAM consumption doubles - 𝑂(𝑛) in order of notation, halfing the concurrency.
Three: The memory ceiling
Concurrency_memory = Available_VRAM / KV_per_request
This is the theorithical maximum memory exhaustion.
Four: vLLM introduces the concept of batching. This allows you to constrain the ceiling of concurrency from the configuration.
Concurrency_batch = min(max_num_seqs,max_num_batched_tokens /avg_tokens_per_request)
And finally, Five: the concurrency is guarded by the tightest contrain
Concurrency_effective =min(Concurrency_memory, Concurrency_batch, max_num_seqs)
For this project, we expect the average_token_per_request for deeper reasoning using the qwen3-14B to be 2000 tokens. For the classification substrate using qwen2.5-3B, the batch is set to 4096 with average_token_per_request set to 1000. Therefore, the batch limit is simply:
Deeper reasoning: Batch limit = 8192 / 2000 ≈ 4
Basic reasoning: Batch limit = 4092 / 1000 ≈ 4
That is it, 4 is the total concurrency expected on 32GB VRAM hosting Qwen2.5-3B and Qwen3-14B.
The same fundamentals ge here can be scaled to Nvidia H100 which has 80GB VRAM.
**The Architecture **
LLM - Qwen3 14B AWQ
command:
[
"Qwen/Qwen3-14B-AWQ",
"--served-model-name", "qwen3-14b",
"--quantization", "awq_marlin",
"--dtype", "float16",
"--gpu-memory-utilization", "0.60",
"--max-model-len", "4096",
"--max-num-seqs", "6",
"--max-num-batched-tokens", "8192",
"--kv-cache-dtype", "fp8",
"--enable-prefix-caching"
]
SLM - Qwen 2.5 3B
command:
[
"Qwen/Qwen2.5-3B-Instruct",
"--served-model-name", "qwen3-3b",
"--dtype", "float16",
"--gpu-memory-utilization", "0.30",
"--max-model-len", "4096",
"--max-num-seqs", "2",
"--max-num-batched-tokens", "4096",
"--kv-cache-dtype", "fp8",
"--enable-prefix-caching"
]
For Embeddings - BGE-EMB:
command:
[
"--model", "BAAI/bge-base-en-v1.5",
"--served-model-name", "bge-emb",
"--gpu-memory-utilization", "0.05",
"--max-model-len", "512"
]
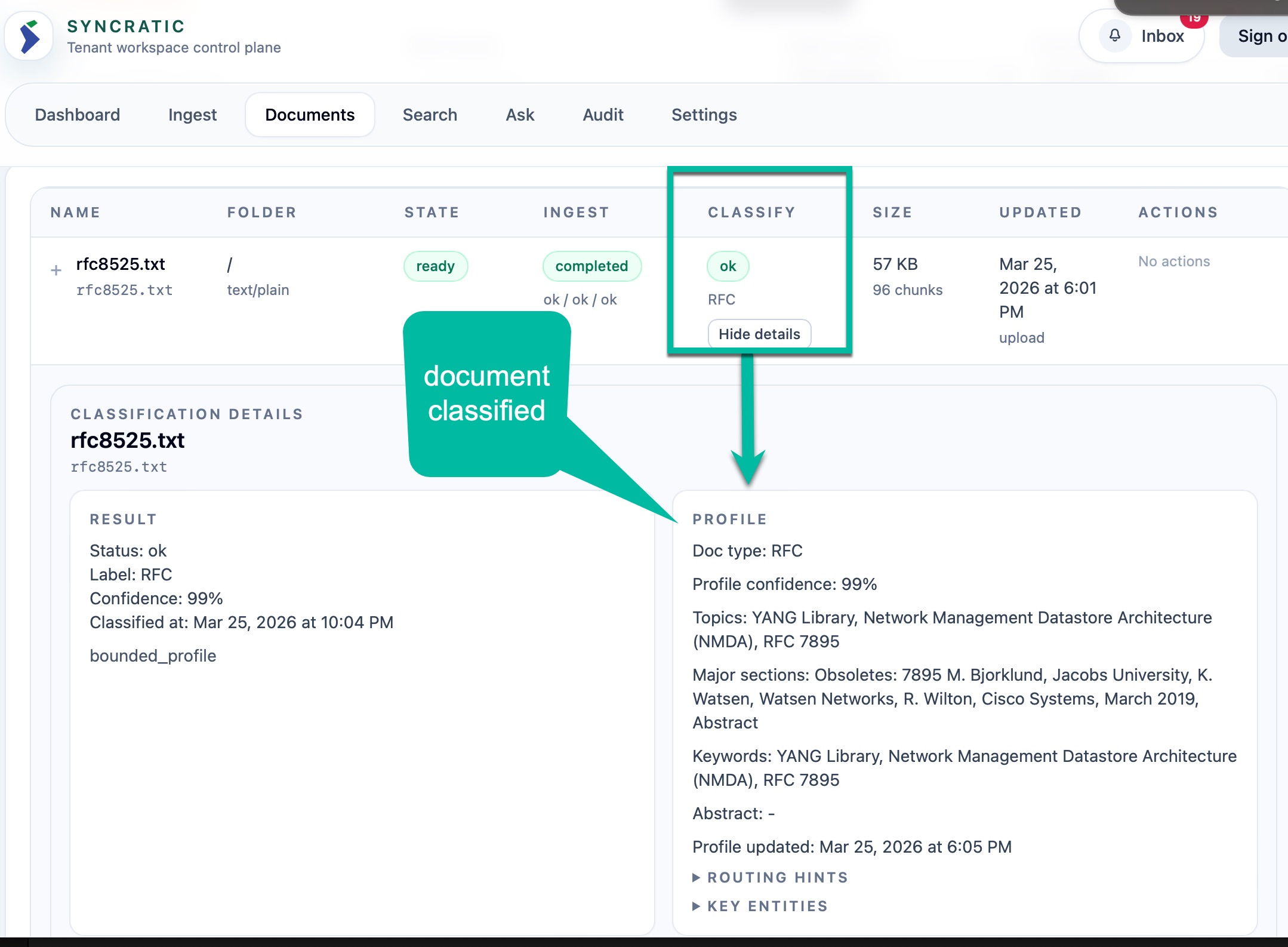
Here is the simple workflow of how SLM and LLM are used to great effect while maximizing VRAM with the above configuration for the core modalities:
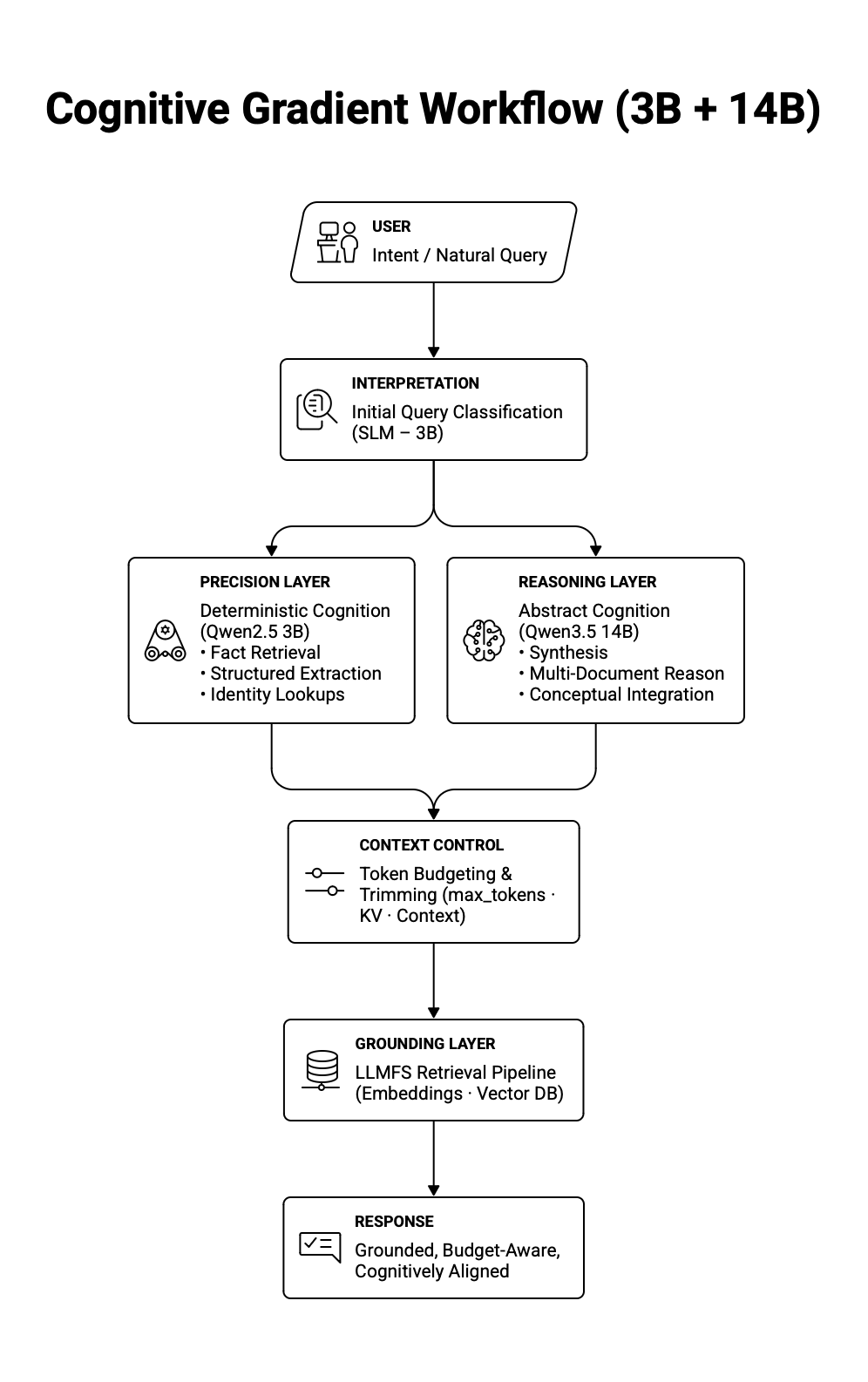
Before classification with SLM
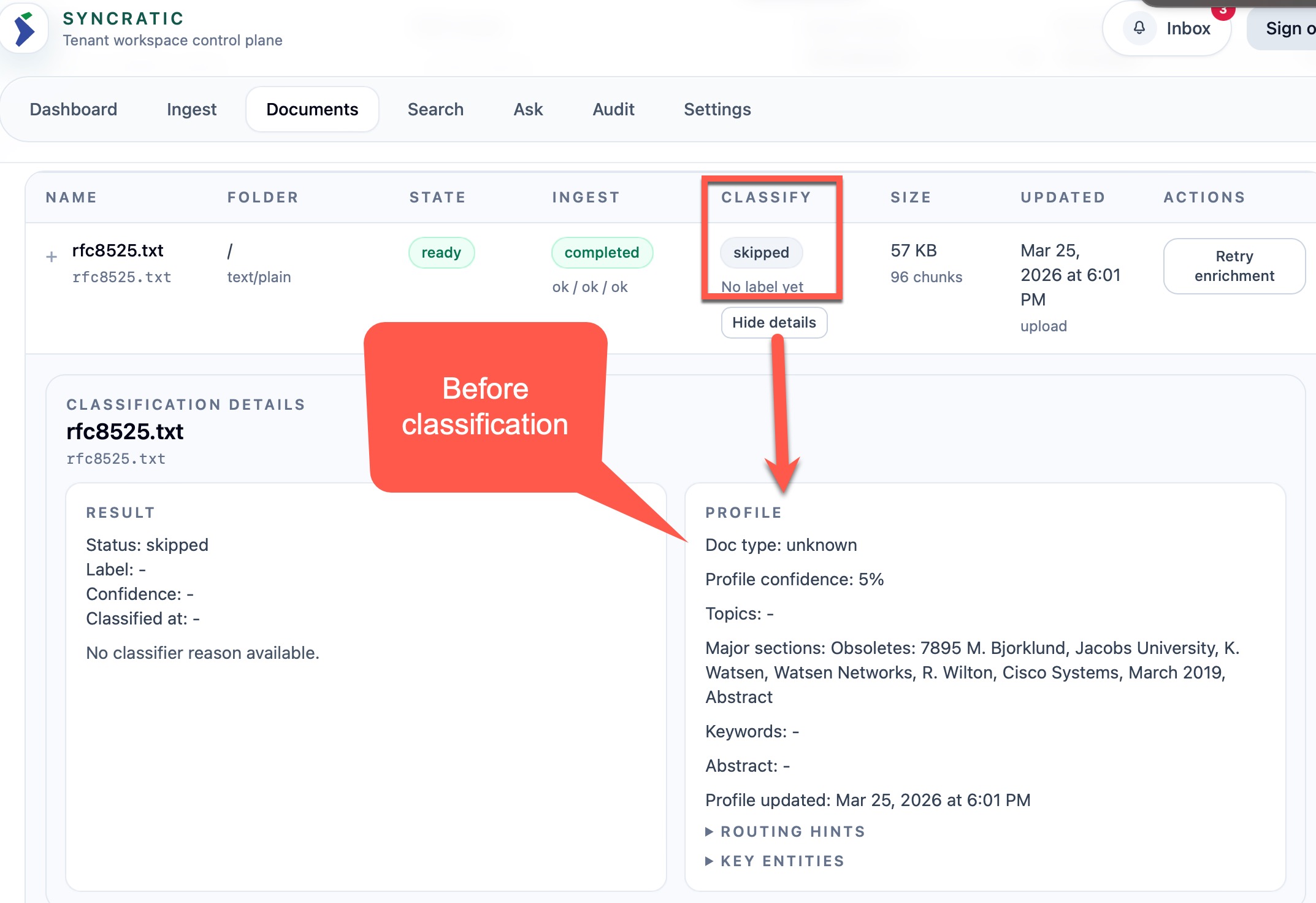
After:
Conclusion
As we move toward an age of efficiency through the adoption of AI for intelligent automation, it is critical that the infrastructure powering that intelligence is itself built on the principles of efficiency.
The future of AI infrastructure will not be defined by the largest model running on the most powerful GPU. It will be defined by systems that understand how cognition flows — when to compress, when to expand, when to reason deeply, and when to remain literal.
True intelligence at scale is not achieved by removing constraints. It is achieved by aligning them.
The systems that endure will not be those that maximize parameters, but those that maximize coherence — where architecture, hardware, retrieval, and reasoning operate as a unified gradient rather than as isolated components. Careful attention must be paid to use cases, with the understanding that one size does not fit all. Scaling to a larger model is rarely the solution to architectural misalignment; thoughtful system design is what enables scalable outcomes.
In the end, it is easy to think that simply spending more on accumulating GPU clusters and for high VRAM is a necessary exercise to fulfiling building scalable intelligent systems. Efficiency must be a foundational driving principle.